
LSIチップとFPGA:量子コンピューター超えを実現
LSI chips and FPGAs: surpassing quantum computers
LSI 晶片和 FPGA:超越量子計算機
ー東京理科大が開発した’LSIシステム’
ー組合せ最適化問題を、低電力で高速に
ニュースイッチ掲載記事からSummaryをお届けします。
東京理科大学:河原尊之教授
量子コンピューターを超える計算能力を持つLSIシステムを開発した。
1.回路線幅22nmのCMOSを使用。
2.4096ビットでスケーラブル

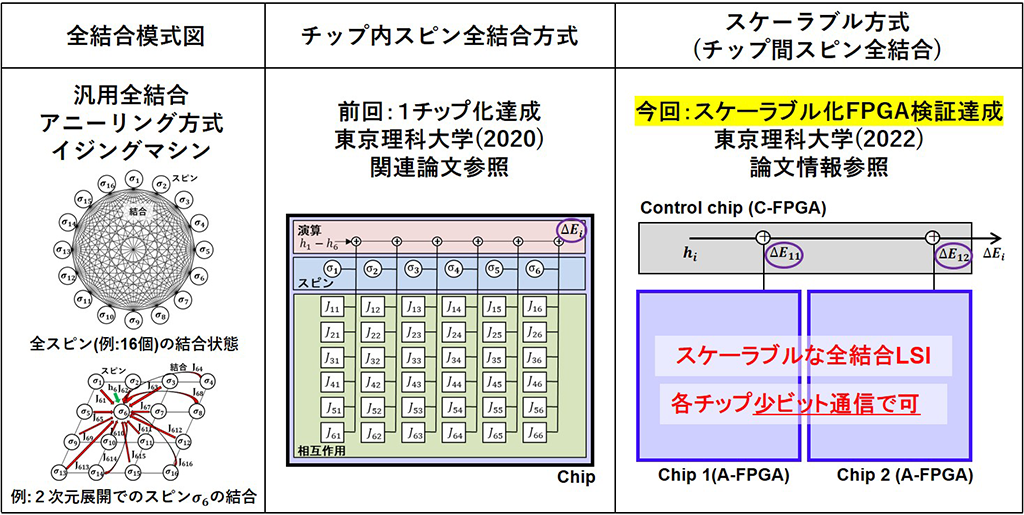
全結合型イジングLSIシステム:
複数チップを並列動作させ、機能拡張した。
大型設備のクラウドサービスを使わずに、大規模計算が可能だ。
河原教授らが開発したのは、スケーラブルな全結合型の「イジングLSIシステム」
演算機能を分散処理:
複数LSIチップをつないで機能拡張する。
1.これまで1チップ内に収まっていた演算機能を、複数チップに分散させた。
2.複数の汎用CMOSに分けて接続する。
’演算機能を複数チップに拡張可能なこと’を、実機で証明した。
LSIチップとFPGA:
今回、22ナノCMOSを使って作製した。
1.演算LSIチップ36個を搭載する。
2.制御用FPGA(=演算回路書き換え可能)を1個を結合。
4096ビットの大規模システム:
3.ビット数が、4096個の大規模システムを試作した。
4.これは、現状のゲート方式量子コンピューターを上回る。
’チップ数を半減できる新たな実装方式’を採用して、集積度を高めた。
4096頂点の「頂点被覆問題」:
組合せ最適化問題の一つ。
’4096頂点の頂点被覆問題’が、簡単に解けることを確認した。
目標は、量子コンピューター越え:
2030年ごろまでに、ビット数を2メガ(メガは100万)個まで増やす。
2050年ごろに実現する量子コンピューター以上の計算能力を目指す。
超電導方式・量子コンピューターの難点:
量子コンピューターは、組み合せ最適化問題を解くのが得意だ。
超電導方式では、極低温に冷やす大規模な装置が必要。
シリコン半導体・LSIシステムの利点
これに対し、既存シリコン半導体のLSIで、同じ計算が可能になった。
創薬や材料開発、物流や金融、マーケティングなど、現場で手軽に使える。
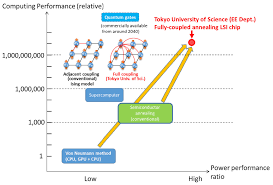
スケーラブルな全結合型イジング半導体システム
東京理科大学掲載記事からSummaryをお届けします。
研究要旨とポイント:
組み合わせ最適化問題を、低消費電力かつ高速に解く技術を開発した。
量子効果を用いないアニーリング方式:
量子Inspired技術の一つ’量子効果を用いないアニーリング方式’を開発。
今回、アニーリング方式で、全結合型イジング半導体システムの大規模化を実現。
’LSIチップ用いたスケーラブル化技術の原理’を検証した。
LSIチップで大容量化すれば、組み合わせ最適化問題に必要な性能を早期に実現できる。
強磁性体スピンの性質利用:
組合せ最適化問題を総当たり法で解くと、膨大な計算資源が必要だ。
’を表すイジングモデル手法’がこれを解決する。
1.高温では、スピンは乱雑な向き
高温の場合、’磁化が発現していない強磁性体のスピン’は、乱雑な向きになる。
2.低温では、スピンの向きが揃う
温度を下げると、すべての可能性を試さなくても、’相互の結び付き’に従う。
つまり、自然にスピンの向きが揃い、磁化が発現する。
この性質を、組み合わせ最適化問題の解法に応用するのだ。
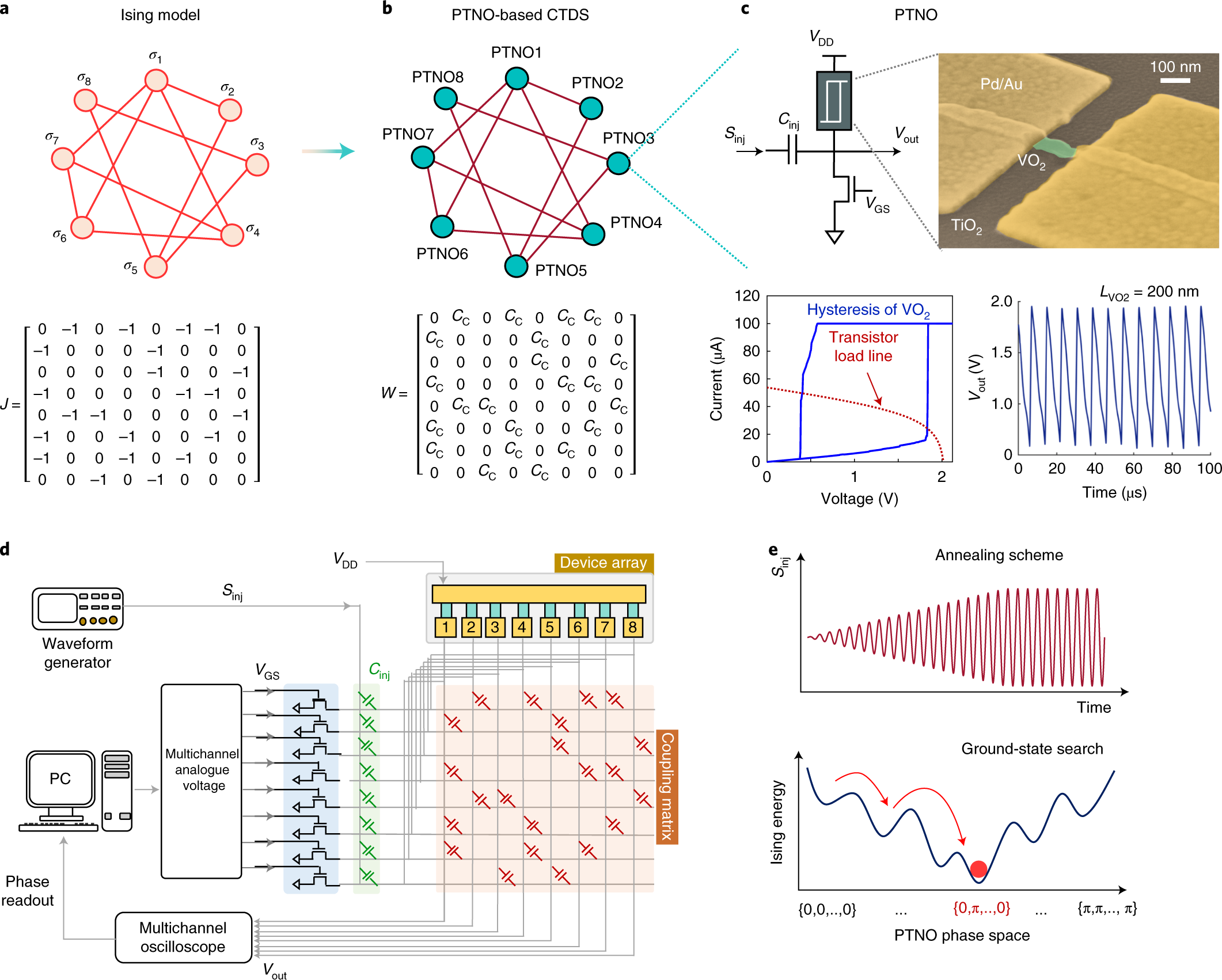
この量子Inspired技術:
実は、日本が得意な重要技術分野なのだ。
強磁性体モデルを、そのまま利用するのではない。
1.’全てのスピンを結合させる全結合型’とする。
2.小実装面積で、実現できる(=隣接結合型の場合、全結合スピン数の二乗個の数が必要)
3.汎用性が高く、広範囲の問題を解ける(=問題を解くための変換処理がシンプル)

512個の全結合型スピンを搭載:
2020年、新チップアーキテクチャを実現した。
国際学会IEEE:SAMI 2020
512個の全結合型スピンを搭載した。
全結合型半導体アニーリング方式のAIチップを発表。

今回の研究結果詳細:
今回、大規模イジングLSIシステムをスケーラブルに構成する方法を考案した。
極めて少数のチップ間接続本数で、複数の全結合イジングLSIチップを結合。
アニーリング方式を用いたひとつの全結合システムとして動作させる。
さらにFPGAを用いて、この手法が正しく動作することを実証した。
アニーリング方式を用いた全結合型で、スケーラブル化を実現した初めてのもの。

今回開発した主要な技術:
エネルギー計算を分割して行い、スピンを更新する手法を考案。
2種類のチップを用い、
同一の複数の第1チップで、エネルギーを分割して計算する。
それらの合計をひとつの第2チップで行う。
更新するスピンの値を決定する新しい方法です。
全体でひとつの全結合システムとして、動作する。
スケーラブルな全結合型システム:
第1と第2のチップ間のデータ通信量を非常に少なくできる。
アニーリング方式として初めて、スケーラブルな全結合型システムを実現した。

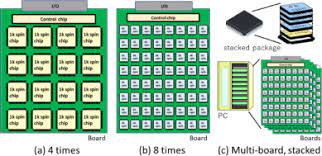
実機での原理検証:
第1のチップとして、16個のFPGAチップ(A-FPGA)と、
第2のチップとして、1個のFPGAチップ(C-FPGA)と用いて、
384スピンの完全結合アニーリング処理システムボードを作成しました(図2)
ひとつの全結合型LSIシステムとして動作し、少量通信で複数チップでの動作が可能であることを確認。
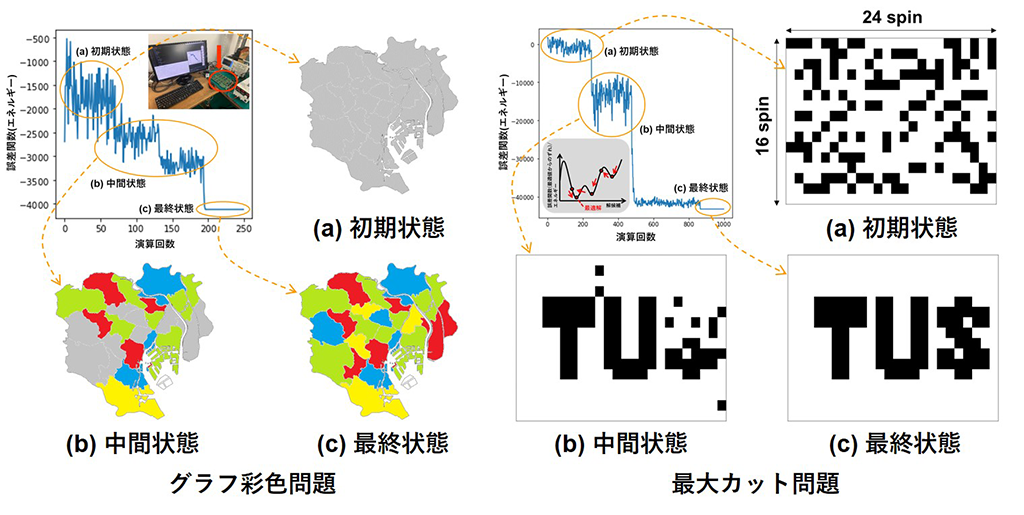
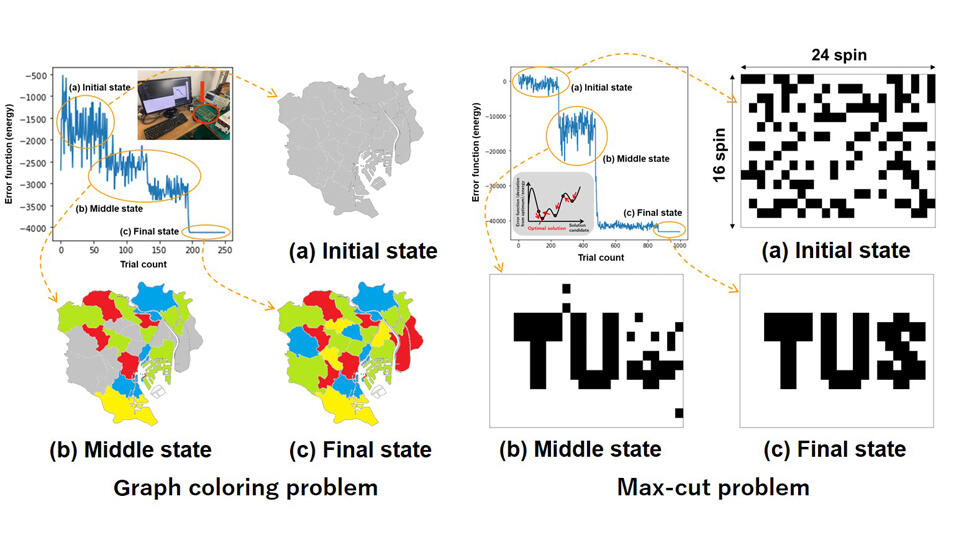
92ノードのグラフ彩色問題:
この実機システムを使用して解けたことを示した。
384ノードの最大カット問題:
最大カット問題においては、
4GHzCPUのPCで、全結合アニーリング計算よりも584 倍高速で、46 倍エネルギー効率が高い性能を実現した(図3)
今後の展望:
今回FPGAを用いて原理検証を成功させた。
今後カスタムLSIチップを用いて大容量化し、性能及び電力効率を大きく高める。
新素材開発や創薬分野で必要な高い性能を早期実現する。